
처음 공부해보는 내용인데 너무 어려운 주제였어서 완전히 틀린 글 일수도 있습니다...
<서론>
이번에 깃허브 API를 이용해서 깃허브 맞팔 탐지기를 만들거나 친구들 끼리 깃허브 활동 내역을 통해서 랭킹 경쟁을 할 수 있는 사이드 프로젝트를 진행 하게 되었다.

우리 서비스 특성 상 모든 유저는 깃허브 사용자라는 전제가 있고 깃허브에서 사용자 프로필 조회 시 사용자의 깃허브 상 고유 ID를 넘겨 주기 때문에 이 ID를 유저의 기본키로 사용하자 라는 의견이 나왔다.
즉, 깃허브에서 UserId를 넘겨주는데 우리가 굳이 새로운 인조키를 만들 필요가 있냐는 것이었다. 깃허브에서 넘겨주는 Id도 123456 같은 정수로 된 인조키이기 때문에 크게 문제가 될 부분이 없어 보였다.
그런데 같은 백엔드 팀원 분이 우리 MySQL 클러스터링 인덱스 사용할텐데 이거 기본키 이렇게 AutoIncrement로 정하지 않고 깃허브에서 주는 1252151613, 1136436346 같은 값으로 썻을 때 성능상 문제가 안 생기겠죠? 라는 질문을 하셨는데 이 질문에 대해서 대답을 할 수가 없었다.
<MySQL InnoDB의 클러스터링 인덱스>
우리 서비스에서는 회원의 정보를 MySQL에 저장한다. 내가 사용하게 될 MySQL은 크게 실제 SQL을 분석하고 실행 계획을 세우는 MySQL엔진과 실제 데이터를 디스크에 저장하거나 읽어오는 스토리지 엔진으로 구성되어 있다.

스토리지 엔진에는 여러 종류가 있는데 최신 MySQL에서는 특별히 따로 스토리지 엔진을 설정하지 않으면 테이블을 생성할 때 보통 InnoDB를 기본으로 사용하게 된다. 여러가지 스토리지 엔진이 있지만 최근에는 InnoDB가 최고의 스토리지 엔진으로 평가 받는 것 같고 MySQL 스토리지 엔진 == InnoDB 정도로 생각해도 될 것 같다.
InnoDB 스토리지 엔진은 다른 엔진들과는 다르게 데이터를 저장할 때 모든 테이블이 기본키를 기준으로 클러스터링되어 저장된다는 특성을 갖는다. 그런데 나는 이 말이 도대체 무슨 소리인지 이해할 수가 없었다.
클러스터링은 인공지능 공부할 때 한번 들어 봤던 것 같다. 아마 무감독 학습에서 비슷한 데이터끼리 묶을 때 클러스터링 한다고 불렀던 거 같다. 뭔지는 몰라도 데이터를 저장할 때 기본키가 비슷한 애들끼리 묶어서 저장한다는 소리인거 같다.

InnoDB의 경우 기본으로 파일 I/O를 위해서 16KB정도의 단위를 사용한다. 즉 데이터를 페이지 단위로 읽어오게 된다. InnoDB의 클러스터링 인덱스의 목표는 기본키가 비슷한 데이터 끼리 실제 저장소에 저장할 때 비슷한 위치에 저장해 두고 기본키가 비슷한 데이터는 자주 같이 조회될 확률이 높으니 메모리에 캐시해 두고 Disk I/O를 줄여보자는 것에 있는 것 같았다.

이런식으로 아무렇게나 데이터가 3번 입력된다고 하고 입력되려는 레코드 3개의 용량이 16KB라고 가정하면

실제 저장소에 데이터를 저장할 때 비슷한 기본키를 가진 데이터들을 물리적으로 가까운 위치에 저장하는 것 같다. 클러스터링 인덱스를 위해 B+ 트리를 이용하는데 B트리 자체는 나중에 하나의 글로 다뤄볼 생각이다.

id = '배1' 인 데이터를 검색할 경우 MySQL에서 저장소에 있는 데이터를 위와 같이 배1 과 같은 페이지에 있는 데이터로 퍼가서 메모리에 올려두고, 추후 어차피 너 '배1' 검색 했으면 '배2'도 검색할거 아니야?? 라는 생각으로 '배2' 요청 시에는 디스크 I/O 없이 '배2'를 빠르게 반환 해 줄 수 있게 만드려는 계획인것 같다.
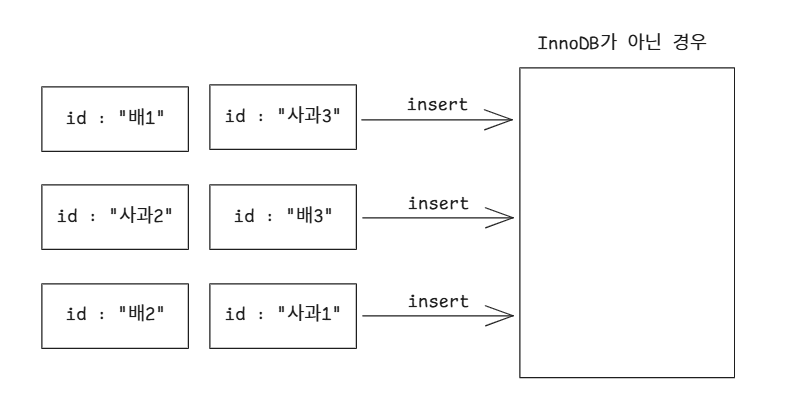
만약 같은 시나리오에서 MySQL 스토리지 엔진이 InnoDB가 아니라면?

이런식으로 실제 물리 저장소에 기본키 기준으로 서로 관련 없는 데이터가 순차적으로 붙어서 저장 되어 버릴 것 같다.

id = '배1'인 데이터를 조회할 때 페이징 사이즈만큼 데이터를 퍼가게 되면 위의 그림 같이 퍼갈거고 다음에 id = '배2'인 데이터를 검색하게 되면 MySQL의 메모리에 해당 데이터가 존재하지 않으니 또 디스크 I/O가 발생할 것 같다.
즉, InnoDB 클러스터링 인덱스라는 건 비슷한 기본키를 가진 레코드들은 조회도 같이 될거니까 물리적으로 비슷한 곳에 저장해 두면 쓸모없는 디스크 I/O를 줄일 수 있을거야 라고 생각해서 만든 것 같다.
<Auto Increment로 기본키를 사용할 경우>
문득 대부분 프로젝트에서 기본키를 위해서 Auto Increment를 사용하던데 이럴 경우 어차피 데이터가 1, 2, 3, 4, 5, 6 ... 같은 순서로 저장될테니 InnoDB 쓰나마나 똑같이 id가 비슷한 애들 순으로 저장되지 않나? 라는 생각이 들었다.

어차피 이런식으로 id가 비슷한 애들끼리 물리적으로 가까운 위치에 저장되는게 보장 될텐데 Auto Increment에는 필요 없는 내용 아닌가? 라는 생각이 들었다.


하지만 데이터가 삭제되는 경우 해당 데이터가 저장된 공간이 비어버리고 새로 들어오는 데이터가 이 자리를 대체 할 수 있었다.

InnoDB 였다면 이런 변경 사항에도 굴하지 않고 id가 같은 애들 끼리 페이지 재 조정이 일어났을 것이다. 따라서 AutoIncrement를 쓴다고 InnoDB의 클러스터링 인덱스 방식을 대체하는 건 아닐거다. 물론 실제 각각의 페이징 같은건 B+ 트리를 통해서 결정 될거다. 위는 단순 예시이다.

실제로 더미 데이터를 100만개 정도 넣어두고 B+트리정보를 조회해 보니 리프노드가 5000개, 페이지 사이즈가 6000개쯤 되었다. 즉 한 페이지에 데이터가 100만 / 5000 = 200 개씩 저장 되었다. 아마 내 더미 데이터에서 16KB는 200개의 레코드였나 보다. 페이지 size가 리프노드 보다 1000개쯤 더 있는 걸로 보아 B+ 트리에서 브랜치 노드들이 1000개쯤 되었나 보다.
<InnoDB 에서 기본키로 Auto Increment 쓰는 것과 깃허브에서 주는 ID 선택하기>
다시 내가 처음에 고민이었던 우리 서비스에서 기본키를 1,2,3 ... 이렇게 Auto Increment로 쓰다가 깃허브에서 제공해주는 깃허브 유저 ID인 1251252, 13636236, 6437477 이런 걸로 대체해 버리면 어떤 Side Effect가 발생할까?로 돌아왔다.
크게 Users 테이블에서 회원가입으로 새로운 User가 등록되는 경우와 회원관련 해서 조회가 발생할 경우로 나눠서 생각해 봐야할것 같았다.
우선 AI(1,2.3...)를 사용하든 Github Id(1001361316, 3745747474 ...)를 사용하든 차이점은 데이터 조회에서는 없을 것 같았다. 우리 프로젝트에서는 각 테이블의 기본키로 우선 인조키를 사용하기로 했다. 기본키에 큰 의미를 두고 있지 않다.
즉, 기본키가 1, 2, 3인 데이터가 물리적으로 비슷한 위치에 저장되어 있어서 16KB씩 조회를 할 때 항상 같이 다닌다고 해보자. 이게 의미가 있을까? 라는 생각이 든다. 우리 서비스에 id가 N인 회원부터 M인 회원 까지 Range 조회 해주세요 같은 요구사항은 존재하지 않는다.
즉, 기본키로 클러스터링 인덱스를 만드는건 좋은데 id =1, id =2 인 회원과 id=1, id=100인 회원 간에 서로 어떤 연관성도 없을 것 같아서 id를 1,2,3 ...으로 설정하나 1251216, 1361636, 46768585으로 설정하나 아무런 차이가 없을 것 같다. 그냥 우연히 id가 1인 회원을 조회했는데 운좋게 id가 2인 회원 조회 요청이 들어오는 경우가 아니라면 이게의미가 있을까? 라는 생각이다.
두번째로 회원 가입은 조금 생각해볼 문제라고 생각했다. Auto Increment 방식에서는 새로운 회원이 가입하면 항상 기존의 어떤 회원들 보다 id가 크기 때문에 B+ 트리에서 오른쪽으로만 쭉쭉 던지면 되니까 좀 좋아 보이긴 했다.

그런데 B+ 트리에서 데이터가 추가된다고 리프노드가 이런식으로 만들어지지는 않을거다.

그냥 예시라 틀린걸 수도 있지만 페이지 하나 새로 만들어서 데이터 하나 딸깍 들어오는 게 아니라 전체적으로 각각의 리프 노드들이 최소로 가져야할 데이터 수를 기준으로 조정이 될거라고 생각한다. 따라서 Auto Increment라고 해서 B+ 트리의 조정이 데이터 삽입시 엄청나게 간단해 진다거나 그런 이점은 없지 않을까 싶다.
깃허브 Id (112516136, 3163674 , 164637)를 사용한다면 새로운 회원이 가입될 경우 Id가 기존 회원들 보다 클지, 작을지, 어떤 Id들 사이에 있을지 예상 할 수가 없어서 트리의 조정이 조금 더 자주 발생 할 수는 있을 것 같다. 하지만 회원 테이블은 다른 테이블에 비해서 데이터가 엄청나게 많이 자주 생성되는 테이블은 아니라고 생각한다.
특히나 클러스터링 인덱스에 데이터를 하나 삽입하는데 이런 문제가 발생해서 사용자가 느낄 만큼 성능저하가 체감이 되려면 정말 엄청나게 많은 회원이 우리 DB에 있어야 하지 않나? 라는 생각이다. 또한 여러 데이터를 벌크성으로 넣는 것도 아니고 유저 한명 insert 하는데 엄청난 성능 저하가 발생할까 싶었다.
<결론>
우리 서비스는 사용자가 어떤 요청을 날렸을 때, 사용자의 OAuth Access Token을 통해서 깃허브에 API를 날리고 받아온 결과를 통해서 처리해 줘야하는 것들이 많다.
문제는 깃허브에서는 우리 서비스에서 자체적으로 만든 유저 ID는 알수가 없기 때문에 개발을 하다보니 userId(1,2,3...)을 통해 DB에 가서 github_userId(125161634, 32636346...)를 조회해 와야하는 번거로운 과정이 계속 발생했다. 반대의 경우도 자주 발생했다.
만약 깃허브 Id를 우리 DB의 회원 Id로 통합한다면 이런 번거로운 문제가 줄어들어 코드치기가 편해지고 불필요한 DB 커넥션 한번이 줄어들고 JPA의 Identity 전략도 사용하지 않아도 되니 회원 가입시 DB에 다음 Auto Increment Id를 알아내기 위한 작업도 줄어들지 않을까? 라는 생각이다.
즉, 성능상으로 크게 포기해야 할점도 없는 것 같고 개발 편의성 증가, 불필요한 DB 커넥션 감소등 장점이 더 많을 것 같아서 Id를 Auto Increment에서 깃허브 Id로 변경하는게 좋아보였다.
UserId를 변경하는 게 이렇게 심오한 일인줄 몰랐습니다. 처음 생각해 보는 주제라서 글의 내용자체가 다 틀렸을 수도 있습니다...
<ref>
Real MySQL 8.0 (1권) - 예스24
『Real MySQL 8.0』은 『Real MySQL』을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0의 GTID와 InnoDB 클러스터 기능들과 소프트웨어 업계 트렌드를 반영한 GIS 및 전문 검색 등의 확장 기능들을 추가로
www.yes24.com